
Robots.txt Nedir? Nasıl Oluşturulur?

Robots.txt, bir web sitesindeki en basit dosyalardan biridir, ancak aynı zamanda karışıklık yaratmanın en kolaylarından biridir. Olmaması gereken tek bir karakter bile SEO üzerinde hasara yol açar ve buda arama motorlarının sitenizdeki önemli bir içeriğe erişmesini engeller.
Bu yüzden robots.txt yanlış yapılandırmaları son derece yaygındır. Deneyimli SEO uzmanları arasında bile…
Yazı İçi Başlıklar
- 1 robots.txt Dosyası Nedir?
- 2 robots.txt Dosyası Nasıl Görünür?
- 3 Kullanıcı Ajansı
- 4 Direktifler
- 5 robots.txt dosyası gerekli mi?
- 6 Nasıl robotlar bulmak için.txt dosyası
- 7 Bir robots.txt dosyası oluşturun!
- 8 robots.txt dosyası nerededir?
- 9 Robots.txt dosyası en iyi uygulamalar
- 9.1 Her Yönerge için yeni bir satır kullanın
- 9.2 Talimatları basitleştirmek için joker karakterler kullanın
- 9.3 URL’nin sonunu işaretlemek için ” $ ” kullan
- 9.4 Her kullanıcı aracısını yalnızca bir kez kullanın
- 9.5 Kasıtsız hataları önlemek için özgüllük kullanın
- 9.6 İnsanlara robots.txt dosyasını açıklamak için yorumları kullanın
- 9.7 Her alt alan için aynı robots.txt dosyasını kullanın
- 10 Örnek robots.txt dosyaları
- 10.1 Tüm botlar için tüm erişim
- 10.2 Tüm botlara erişim yok
- 10.3 Tüm botlar için bir alt dizini engelle
- 10.4 Tüm botlar için bir alt dizini engelle (izin verilen bir dosya ile)
- 10.5 Tüm botlar için bir dosyayı engelle
- 10.6 Tüm botlar için bir dosya türünü ( PDF ) engelle
- 10.7 Yalnızca Googlebot için tüm parametreli URL’leri engelle
- 10.8 Gönderilen URL robots.txt tarafından engellendi!
- 10.9 robots.txt tarafından engellendi.
- 10.10 Endeksli, robots.txt tarafından engellenmiş ise;
- 11 SSS
robots.txt Dosyası Nedir?
Robots.txt dosyası, arama motorlarına sitenizde nereye gidebileceklerini ve gidemediklerini söyler.
Öncelikle, Google gibi arama motorlarından kilitlemek istediğiniz tüm içeriği listeler. Bazı arama motorlarına (Google değil) izin verilen içeriği nasıl tarayabileceklerini de söyleyebilirsiniz.ÖNEMLİ NOT
Çoğu arama motoru itaatkardır. Bir girişi kırma alışkanlığı içinde değiller. Bununla birlikte, bazıları birkaç mecazi kilit seçmek konusunda utangaç değildir.
Google bu arama motorlarından biri değildir. Bir robots.txt dosyasındaki talimatları uygular.
Sadece bazı arama motorlarının tamamen görmezden geldiğini bilin.
robots.txt Dosyası Nasıl Görünür?
İşte bir temel biçinde robots.txt dosyası:
Site haritası: [site haritasının URL konumu] Kullanıcı Aracısı :[ bot tanımlayıcısı] [Yönerge 1] [Yönerge 2]
[direktif. ..]
Kullanıcı Aracısı :[ başka bir bot tanımlayıcısı] [Yönerge 1] [Yönerge 2]
[direktif. ..]
Daha önce bu dosyalardan birini hiç görmediyseniz, bu zor görünebilir. Ancak, söz dizimi oldukça basittir.
Kısacası, kullanıcı aracısını ve ardından yönergeleri belirterek botlara kurallar atarsınız .
Bu iki bileşeni daha ayrıntılı olarak inceleyelim.
Kullanıcı Ajansı
Her arama motoru kendini farklı bir kullanıcı aracısı ile tanımlar. Bunların her biri için özel robots.txt talimatlarI ayarlayabilirsiniz . Yüzlerce kullanıcı Aracısı var, ancak SEO için faydalı olanlar:
- Google: Googlebot
- Google Images: Googlebot-Görüntü
- Bing: Bingbot
- Yahoo: Slurp
- Baıdu: Baiduspider
- DuckDuckGo: DuckDuckBot
Tüm kullanıcı aracıları robots.txt dısyakaru büyük / küçük harf duyarlıdır.
Tüm kullanıcı aracılarına yönergeler atamak için yıldız (*) joker karakterini de kullanabilirsiniz.
Örneğin, Googlebot dışındaki tüm botların sitenizi taramasını engellemek istediğinizi varsayalım. İşte bunu nasıl yaparsın:
User-agent: * İzin vermemek: / Google'ın User-agent: Vermek: /
Senin robots.txt dosyanda, istediğin kadar kullanıcı aracısı için direktifler içerebilir. Bununla birlikte, yeni bir kullanıcı aracısı her bildirdiğinizde, temiz bir sayfa görevi görür.
Başka bir deyişle, birden çok kullanıcı Aracısı için yönergeler eklerseniz, ilk kullanıcı aracısı için bildirilen yönergeler ikinci veya üçüncü veya dördüncü vb. için geçerli değildir.
Bu kuralın istisnası, aynı kullanıcı aracısını birden çok kez bildirdiğinizde olur. Bu durumda, ilgili tüm direktifler birleştirilir ve takip edilir.
ÖNEMLİ NOT
Tarayıcıların yalnızca en doğru şekilde uygulanır kullanıcı aracıları altında bildirilen kurallara uyun . Bu yüzden yukarıdaki robots.txt dosyası, Googlebot (ve diğer Google botları) dışındaki tüm botların siteyi taramasını engeller. Googlebot daha az özel kullanıcı aracısı bildirimi yok sayar.
Direktifler
Yönergeler, bildirilen kullanıcı aracılarının izlemesini istediğiniz kurallardır.
Desteklenen yönergeler
Google’ın şu anda desteklediği ve kullanımları ile birlikte direktifleri burada bulabilirsiniz.
İzin vermemek
Arama motorlarına belirli bir yolun altına giren dosyalara ve sayfalara erişmemesini sağlamak için bu yönergeyi kullanın. Örneğin, tüm arama motorlarının blogunuza ve tüm yayınlarına, erişmesini engellemek istiyosanız robots.txt böyle görünebilir:
User-agent: * İzin verme: /blog
SİDENOTE.
Disallow yönergesinden sonra bir yol tanımlamazsanız, arama motorları bunu göz ardı eder.
İzin Vermek
Arama motorlarının bir alt dizini veya sayfayı taramasına izin vermek için bu yönergeyi kullanın. Örneğin, arama motorlarının bir tane dışında blogunuzdaki her gönderiye erişmesini önlemek istiyorsanız, o zaman robots.txt dosyası böyle görünebilir:
User-agent: * İzin verme: /blog İzin ver: / blog / izin-post
Bu örnekte, arama motorları erişebilir /blog/allowed-post. Ama erişemiyorlar:
/blog/another-post/blog/yet-another-post/blog/download-me.pdf
Hem Google hem de Bing bu yönergeyi desteklemektedir.SİDENOTE.
Disallow yönergesinde olduğu gibi, izin ver yönergesinden sonra bir yol tanımlamazsanız, arama motorları bunu göz ardı eder.ÇAKIŞAN KURALLAR HAKKINDA BİR NOT
Dikkatli olmadıkça, izin vermemek ve direktiflere izin vermek birbirleriyle kolayca çakışabilir. Aşağıdaki örnekte, erişime izin vermiyoruz /blog/ve erişime izin veriyoruz /blog.
User-agent: * İzin verme: /blog/ İzin ver: / blog
Bu durumda, URL /blog/post-title/hem izin verilmeyen hem de izin verilen gibi görünüyor. Kazanan yani?
Google ve Bing için kural, en çok karaktere sahip yönergenin kazanmasıdır. İşte, bu izin verme yönergesi.
Disallow: /blog/ (6 karakter) Allow: /blog (5 karakter)
Allow ve disallow yönergelerinin uzunluğu eşitse, en az kısıtlayıcı Yönerge kazanır. Bu durumda, bu izin yönergesi olacaktır.SİDENOTE.
Burada, /blog(sondaki eğik çizgi olmadan) hala erişilebilir ve taranabilir.
En önemlisi, bu sadece Google ve Bing için geçerlidir . Diğer arama motorları ilk eşleştirme yönergesini dinler. Bu durumda, bu izin vermez.
Site haritası
Arama motorlarına site haritalarınızın konumunu belirtmek için bu yönergeyi kullanın. Site haritalarına aşina değilseniz, genellikle arama motorlarının taranmasını ve dizine eklenmesini istediğiniz sayfaları içerir.
İşte bir site haritası yönergesini kullanarak robots.txt dosyası örneğ;
Site haritası: https://www.domain.com/sitemap.xml User-agent: * İzin verme: /blog/ İzin ver: / blog / post-title/
Önemli robotlar(lar) haritanız dahil nasıl.txt dosyası? Search Console aracılığıyla zaten gönderdiyseniz, Google için biraz gereksizdir. Ancak, Bing gibi diğer arama motorlarına Site Haritanızı nerede bulacağını söyler, bu yüzden hala iyi bir uygulamadır.
Her kullanıcı Aracısı için Site Haritası yönergesini birden çok kez yinelemenize gerek olmadığını unutmayın.Note that you don’t need to repeat the sitemap directive multiple times for each user-agent. Sadece biri için geçerli değildir. Bu nedenle, robotlarınızın başında veya sonunda site haritası yönergelerini dahil etmek en iyisidir.txt dosyası. Mesela:
Site haritası: https://www.domain.com/sitemap.xml Google'ın User-agent: İzin verme: /blog/ İzin ver: / blog / post-title/ Kullanıcı Aracısı: Bingbot Disallow: / hizmetler/
Google, ask, Bing ve Yahoo gibi site haritası yönergesini destekler.SİDENOTE.
robots.txt dosyanıza istediğiniz kadar site haritası ekleyebilirsiniz.
Desteklenmeyen yönergeler
İşte artık Google tarafından desteklenmeyen direktifler, bazıları teknik olarak hiç olmadı.
Tarama-gecikme
Önceden, saniye cinsinden gezinme gecikmesi belirtmek için bu yönergeyi kullanabilirsiniz. Örneğin, Googlebot’un her tarama eyleminden 5 saniye sonra beklemesini istiyorsanız, tarama gecikmesini 5’e ayarlarsınız:
Google'ın User-agent: Tarama-gecikme: 5
Google artık bu yönergeyi desteklemiyor, ancak Bing ve Yandex bunu yapıyor.
Bu, özellikle büyük bir siteniz varsa, bu yönergeyi ayarlarken dikkatli olun. 5 saniyelik bir tarama gecikmesi ayarlarsanız, botları günde en fazla 17,280 URL taramak için sınırlarsınız. Milyonlarca sayfanız varsa bu çok yararlı değil, ancak küçük bir web siteniz varsa bant genişliğinden tasarruf edebilir.
Noindex
Bu yönerge Google tarafından resmi olarak desteklenmedi. Ancak, yakın zamana kadar, Google’ın desteklenmeyen ve yayınlanmamış kuralları (noindex gibi) işleyen bazı “kodlara sahip olduğu düşünülmektedir.”Google’ın blogunuzdaki tüm yayınları dizine eklemesini önlemek istiyorsanız, aşağıdaki yönergeyi kullanabilirsiniz:
Google'ın User-agent: Noindex: / blog/
Ancak, 1 Eylül 2019’da Google, Bu Yönergenin desteklenmediğini açıkça belirtti . Bir sayfayı veya dosyayı arama motorlarından hariç tutmak istiyorsanız, bunun yerine meta robots etiketini veya X-robots HTTP üstbilgisini kullanın.
Nofollow
Bu, Google’ın resmi olarak desteklemediği ve arama motorlarına belirli bir yol altındaki sayfalardaki ve dosyalardaki bağlantıları takip etmemelerini öğretmek için kullanılan başka bir yönergedir. Örneğin, Google’ın blogunuzdaki tüm bağlantıları izlemesini durdurmak istiyorsanız, aşağıdaki yönergeyi kullanabilirsiniz:
Google'ın User-agent: Nofollow: / blog/
Google, Bu Yönergenin 1st, 2019 Eylül ayında resmi olarak desteklenmediğini açıkladı. Şimdi bir sayfadaki tüm bağlantıları takip etmek istemiyorsanız, robots meta etiketini veya X-robots başlığını kullanmalısınız. Google’a bir sayfadaki belirli bağlantıları izlememesini söylemek isterseniz, rel = “nofollow” bağlantı özniteliğini kullanın.
robots.txt dosyası gerekli mi?
Bir robot olması.txt dosyası, özellikle küçük web siteleri için çok önemli değildir.
Arama motorlarının web sitenizde nereye gidebileceği ve gidemeyeceği konusunda size daha fazla kontrol sağlar ve bu gibi şeylere yardımcı olabilir:
- Yinelenen içeriğin taranmasını önleme;
- Bir web sitesinin bölümlerini gizli tutmak (örneğin, evreleme siteniz);
- Dahili arama sonuçları sayfalarının taranmasını önleme;
- Sunucu aşırı yüklenmesini önleme;
- Google’ın ” tarama bütçesini boşa harcamasını önleme .”
- Google arama sonuçlarında görüntülerin , videoların ve kaynak dosyalarının görünmesini önleme.
Google’ın genellikle robotlarda engellenen web sayfalarını dizine eklemediğini unutmayın.txt, robotları kullanarak arama sonuçlarından dışlanmayı garanti etmenin bir yolu yoktur.txt dosyası .
Google’ın dediği gibi, içerik web’deki diğer yerlerden bağlıysa, Google arama sonuçlarında görünmeye devam edebilir.
Nasıl robotlar bulmak için.txt dosyası
Zaten bir robot varsa.web sitenizde txt dosyası, bu erişilebilir olacak domain.com/robots.txt . tarayıcınızdaki URL’ye gidin. Böyle bir şey görürseniz, o zaman bir robots.txt dosyası var demektir;

Bir robots.txt dosyası oluşturun!
Zaten bir robots.txt dosyası yoksa, yeni bir tane oluşturmak kolaydır. Sadece bir boşluk açın .txt belgesi ve direktifleri yazmaya başlayın. Örneğin, tüm arama motorlarının dizininizi taramasına izin vermemek istiyorsanız/admin/, böyle bir şey görünecektir:
User-agent: * Disallow: / yönetim/
Sahip olduğunuz şeyden memnun olana kadar direktifleri oluşturmaya devam edin. Dosyanızı “robots”olarak kaydedin “txt.”
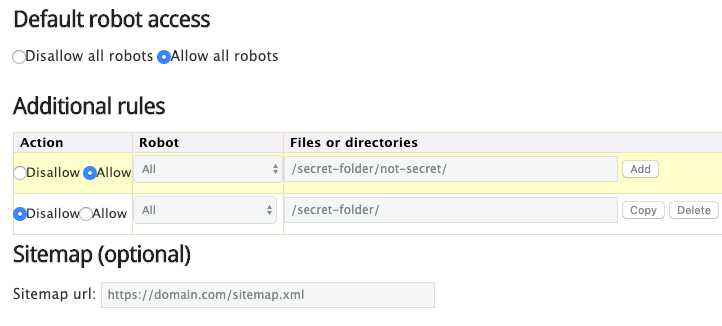
Böyle bir aracı kullanmanın avantajı, söz dizimi hatalarını en aza indirmesidir. Bu iyi çünkü bir hata siteniz için bir SEO felaketine neden olabilir-bu yüzden dikkatli bir şekilde hata yapmak için öder.
Dezavantajı, özelleştirilebilirlik açısından biraz sınırlı olmalarıdır.
robots.txt dosyası nerededir?
Geçerli olduğu alt etki alanının kök dizinindeki robots.txt dosyasına yerleştirin. Örneğin, tarama davranışını denetlemek için domain.com robots.txt dosyası erişilebilir olmalıdır domain.com/robots.txt .
Gibi bir alt alan üzerinde tarama kontrol etmek istiyorsanız blog.domain.com sonra robots.txt dosyası erişilebilir olmalıdır blog.domain.com/robots.txt .
Robots.txt dosyası en iyi uygulamalar
Yaygın hatalardan kaçınmak için bunları aklınızda bulundurun.
Her Yönerge için yeni bir satır kullanın
Her Yönerge yeni bir satıra oturmalıdır. Aksi takdirde, arama motorlarını karıştırır.
Kötü:
Kullanıcı Aracısı: * Disallow: / directory / Disallow: / başka bir dizin/
İyi:
User-agent: * Disallow: / dizin/ Disallow: / başka bir dizin/
Talimatları basitleştirmek için joker karakterler kullanın
Tüm kullanıcı aracılarına yönergeleri uygulamak için joker karakterler (*) kullanmakla kalmaz, aynı zamanda yönergeleri bildirirken URL kalıplarıyla eşleşir. Örneğin, arama motorlarının sitenizdeki parametreli Ürün kategorisi Url’lerine erişmesini önlemek istiyorsanız, bunları şöyle listeleyebilirsiniz:
User-agent: * Disallow: / ürünler / t-shirt? Disallow: / ürünler / hoodies? Disallow: / ürünler / ceketler? …
Ama bu çok verimli değil. Böyle bir joker karakterle işleri basitleştirmek daha iyi olurdu:
User-agent: * Disallow: / ürünler/*?
Bu örnek, arama motorlarının soru işareti içeren /product/ subfolder altındaki tüm URL’leri taramasını engeller. Başka bir deyişle, herhangi bir parametreli Ürün kategorisi URL’leri.
URL’nin sonunu işaretlemek için ” $ ” kullan
Bir URL’nin sonunu işaretlemek için ” $ ” simgesini ekleyin . Örneğin, arama motorlarının hepsine erişmesini önlemek istiyorsanız .sitenizde PDF dosyaları, sizin robotlar.txt dosyası böyle görünebilir:
User-agent: * İzin vermemek.*/ :pdf$
Bu örnekte, arama motorları ile biten herhangi bir URL’ye erişemez .pdf. Bu, erişemedikleri /dosyalayamadıkları anlamına gelir.pdf, ancak erişebilirler / dosya.pdf?ıd = 68937586 çünkü bu ” ile bitmiyor.pdf”.
Her kullanıcı aracısını yalnızca bir kez kullanın
Aynı kullanıcı aracısını birden çok kez belirtirseniz, Google umursamaz. Sadece bir içine çeşitli beyanlar tüm kuralları birleştirmek ve hepsini takip edecektir. Örneğin, robotlarınızda aşağıdaki kullanıcı aracıları ve direktifleri varsa.txt dosyası…
Google'ın User-agent: İzin verme: / a/ Google'ın User-agent: İzin verme: / b/
… Googlebot bu alt klasörlerden hiçbirini taramazdı.
Bununla birlikte, her kullanıcı aracısını yalnızca bir kez ilan etmek mantıklıdır, çünkü daha az kafa karıştırıcıdır. Başka bir deyişle, işleri düzgün ve basit tutarak kritik hatalar yapma olasılığınız azdır.
Kasıtsız hataları önlemek için özgüllük kullanın
Direktifleri ayarlarken belirli talimatları sağlamak için başarısızlık SEO üzerinde felaket bir etkisi olabilir kolayca cevapsız hatalara neden olabilir . Örneğin, çok dilli bir siteniz olduğunu ve /de/ alt dizini altında kullanılabilen bir Almanca sürümü üzerinde çalıştığınızı varsayalım.
Gitmek için oldukça hazır olmadığından, arama motorlarının erişmesini önlemek istiyorsunuz.
Robot.aşağıdaki txt dosyası, arama motorlarının bu alt klasöre ve içindeki her şeye erişmesini önleyecektir:
User-agent: * Disallow: / de
Ama aynı zamanda herhangi bir sayfa veya dosyaları ile başlayan tarama arama motorları engeller /de.
Mesela:
/designer-dresses//delivery-information.html/depeche-mode/t-shirts//definitely-not-for-public-viewing.pdf
Bu durumda, çözüm basittir: sondaki eğik çizgi ekleyin.
User-agent: * Disallow: / de/
İnsanlara robots.txt dosyasını açıklamak için yorumları kullanın
Yorumlar robotlar açıklamaya yardımcı.geliştiriciler için txt dosyası-ve potansiyel olarak gelecekteki benliğiniz bile. Bir açıklama eklemek için satıra bir karma (#) ile başlayın.
# Bu Bing sitemizi taramaya değil bildirir. Kullanıcı Aracısı: Bingbot İzin vermemek: /
Tarayıcılar, bir karma ile başlayan satırlardaki her şeyi göz ardı eder.
Her alt alan için aynı robots.txt dosyasını kullanın
robots.txt yalnızca barındırılan alt etki alanında gezinme davranışını denetler. Farklı bir alt alan üzerinde tarama kontrol etmek istiyorsanız, ayrı bir robots.txt dosyası gerekir.
Örneğin, ana siteniz oturuyorsa domain.com ve blogunuza oturur blog.domain.com o zaman iki robots.txt dosyasına ihtiyacınız olacak. Ana etki alanının kök dizininde gitmeli ve blog kök dizininde başka.
Örnek robots.txt dosyaları
Aşağıda robots.txt dosyaları birkaç örnektir. Bunlar esas olarak ilham içindir, ancak gereksinimlerinize uygun olursa, bir metin belgesine kopyalayıp yapıştırın, “robots.txt” olarak kaydedin ” ve uygun dizine yükleyin.
Tüm botlar için tüm erişim
User-agent: * İzin vermemek:
SİDENOTE.
Bir yönerge bu yönergeyi gereksiz hale getirdikten sonra bir URL bildirilemiyor. Başka bir deyişle, arama motorları bunu görmezden gelir. Bu nedenle bu disallow yönergesinin sitede hiçbir etkisi yoktur. Arama motorları hala tüm sayfaları ve dosyaları tarayabilir.
Tüm botlara erişim yok
User-agent: * İzin vermemek: /
Tüm botlar için bir alt dizini engelle
User-agent: * Disallow: / klasör/
Tüm botlar için bir alt dizini engelle (izin verilen bir dosya ile)
User-agent: * Disallow: / klasör/ İzin ver:/klasör / sayfa.html
Tüm botlar için bir dosyayı engelle
User-agent: * Disallow: / bu-bir-dosya.pdf
Tüm botlar için bir dosya türünü ( PDF ) engelle
User-agent: * İzin vermemek.*/ :pdf$
Yalnızca Googlebot için tüm parametreli URL’leri engelle
Google'ın User-agent: İzin verme:/*?
Gönderilen URL robots.txt tarafından engellendi!
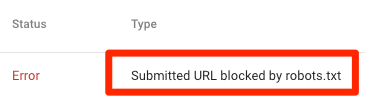
Bu, gönderilen site haritalarınızdaki URL’lerden en az birinin robots.txt tarafından engellendiği anlamına gelir.
Site Haritanızı doğru şekilde oluşturduysanız ve kurallılaştırılmış , noındexed ve yeniden yönlendirilmiş sayfaları hariç tuttuysanız, gönderilen sayfalar robots.txt tarafından engellenmemelidir. Eğer öyleyse, hangi sayfaların etkilendiğini araştırın, ardından robots.txt dosyasınızı ayarlayın.
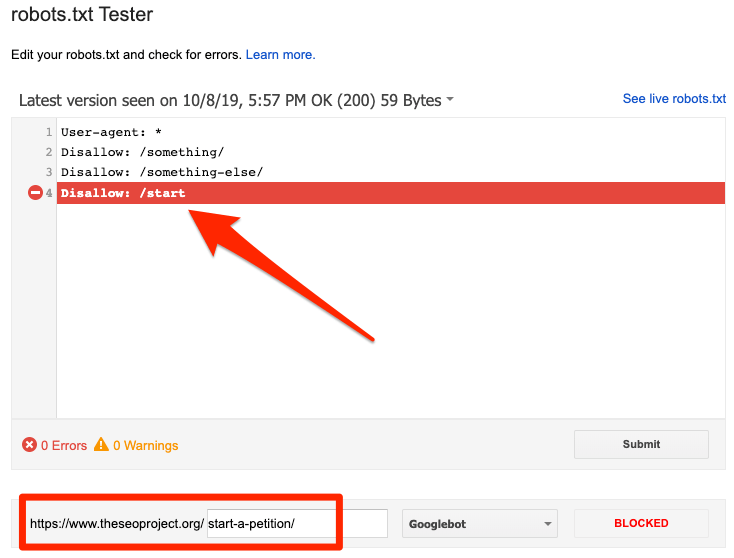
Google’ın robots.txt dosyasını kullanabilirsiniz. Tester hangi yönergenin içeriği engellediğini görmek için. Bunu yaparken dikkatli ol. Diğer sayfaları ve dosyaları etkileyen hatalar yapmak kolaydır.
robots.txt tarafından engellendi.
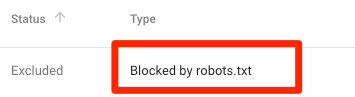
Bu, robots.txt tarafından engellenen içeriğe sahip olduğunuz anlamına gelir.
Bu içerik önemliyse ve dizine eklenmesi gerekiyorsa, robots.txt dosyasındaki gezinme bloğunu kaldırın. (Ayrıca içeriğin noindexed olmadığından emin olmaya değer). Eğer robots.txt dosyasındaki içeriği bloke ettiyseniz, Google’ın dizininden hariç tutma niyetiyle, tarama bloğunu kaldırın ve bunun yerine bir robots meta etiketi veya X‑robots-Başlığı kullanın. İçeriğin Google’ın dizininden dışlanmasını garanti etmenin tek yolu budur.
Bir sayfayı arama sonuçlarından hariç tutmaya çalışırken gezinme bloğunun kaldırılması çok önemlidir. Bunu yapamazsınız ve Google noindex etiketini veya HTTP başlığını görmez—bu yüzden dizine eklenecektir.
Endeksli, robots.txt tarafından engellenmiş ise;
Bu, bazı içeriğin robots.txt tarafından engellendiği anlamına gelir. Yine de Google’da dizine eklenir.
Bir kez daha, bu içeriği Google’ın arama sonuçlarından hariç tutmaya çalışıyorsanız, robots.txt doğru çözüm değil. Tarama bloğunu kaldırın ve bunun yerine indekslemeyi önlemek için bir meta robots etiketi veya X‑robots-tag HTTP Başlığı kullanın.
Bu içeriği kazara engellediyseniz ve Google’ın dizininde tutmak istiyorsanız, robots.txt’de bulunan gezinme bloğunu kaldırın.. Bu, Google arama’daki içeriğin görünürlüğünü artırmaya yardımcı olabilir.
SSS
İşte rehberimizde doğal olarak başka bir yere uymayan birkaç sık sorulan soru. Bir şey eksikse yorumlarda bize bildirin ve bölümü buna göre güncelleyeceğiz.Bir robots.txt dosyasının maksimum boyutu nedir?
Kabaca 500 kilobayt.WordPress’de robots.txt dosyası nerededir?
Aynı yerde, domain.com/robots.txtWordPress’de robots.txt dosyasını nasıl düzenleyebilirim?
Elle veya robots.txt dosyasını düzenlemenize izin veren Yoast gibi birçok WordPress SEO eklentisinden birini kullanarak bunu yapabilirsiniz.robots.txt için noindexed içeriğe erişime izin vermezsem ne olur?
Google, noindex yönergesini asla görmeyecektir çünkü sayfayı tarayamaz.
Bir önceki yazımız olan Tarama Bütçesi (Crawl Budget) Nedir? başlıklı makalemizi de okumanızı öneririz.




